Làm thế nào để tôi có thể sử dụng selenium trên ubuntu server [non-ui].
Giới thiệu
Xin chào $5$ tỷ anh em, mình đang làm $1$ công việc cũng hết sức phổ biến hiện nay là cào dữ liệu. Nhưng vấn đề của mình không hoàn toàn là phải dùng selenium hỗ trợ lấy page source để trích xuất dữ liệu, nhưng để tối ưu nguồn tài nguyên thì mình có $1$ mini-pc đang trống nên mình quyết định dùng nó để phục vụ việc cào dữ liệu.

Mình dùng selenium cũng không nhiều nhưng mình cũng biết 1 số option hỗ trợ tối ưu như:
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--start-maximized") # Mở rộng cửa sổ trình duyệt
chrome_options.add_argument("disable-notifications") # Tắt thông báo
chrome_options.add_argument("--disable-extensions") # Tắt các tiện ích mở rộng
chrome_options.add_argument("--no-sandbox") # Giúp ổn định hơn trên macOS
chrome_options.add_argument("--disable-dev-shm-usage") # Giảm lỗi chia sẻ bộ nhớ
chrome_options.add_argument("--disable-gpu") # Tắt GPU
chrome_options.add_argument("--headless") # Chế độ không hiển thị trình duyệt
chrome_options.add_argument("--incognito") # Chế độ ẩn danh
...
Thì mình nhận thấy option --headless là nó giúp mình chạy driver ngầm mà không cần hiển thị giao diện. Thì lúc này mình mới nảy ra suy nghĩ là: “Nếu option này nó ẩn giao diện đi thì với hệ điều hành ubuntu server kia không có giao diện thì có chạy được selenium không nhỉ?”.
Thế là mình lên google search các kiểu con đà điểu 🧐 và cũng tìm được kha khá solution nhưng đa phần mình không cài được. Loay hoay một hồi thì mình cũng làm được! yeah và hôm nay mình sẽ truyền lại bí kíp này cho các bạn. Vỗ tay cái nhờ 👏👏
Thực hiện
Oke, vậy thì mình bắt đầu với giao diện ngầu lòi của mấy anh hacker mà anh em hằng mong ước trước. Tôi sẽ dùng một số lệnh để xem thông tin máy trước.
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 24.04 LTS
Release: 24.04
Codename: noble
$ hostnamectl
Static hostname: xxxx
Icon name: computer-desktop
Chassis: desktop 🖥️
Machine ID: xxxx
Boot ID: xxxx
Operating System: Ubuntu 24.04 LTS
Kernel: Linux 6.8.0-44-generic
Architecture: x86-64
Hardware Vendor: Default string
Hardware Model: Default string
Firmware Version: 5.13
Firmware Date: Sat 2023-06-10
Firmware Age: 1y 3month 1w 3d
Đầu tiên mình sẽ cập nhật danh sách các gói phần mềm và các phiên bản mới nhất có sẵn từ các kho lưu trữ đã cấu hình trên hệ thống.
$ sudo apt update
Tiếp đó là cài đặt các gói phần mềm wget và unzip để tải và giải nén các tệp tin từ internet.
$ sudo apt install -y wget unzip
Tiếp tục tải về tệp cài đặt Google Chrome từ máy chủ của Google. (tôi hay dùng chrome nếu các bạn xài cái khác thì lên google tìm nhé!)
$ wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
Khi chạy xong thì tệp tin sẽ được tải xuống ở thư mục hiện tại, và mình sẽ phải di chuyển tệp tin này sang thư mục /tmp/.
$ sudo mv ./google-chrome-stable_current_amd64.deb /tmp/
Cuối cùng là cài đặt chrome vào máy.
$ sudo apt install -y /tmp/google-chrome-stable_current_amd64.deb
😜 thật ra cũng không bắt buộc phải di chuyển file vào /tmp/ đâu nhưng mình muốn mọi thứ được sắp xếp hoàn hảo giống như nên biết vị trí của mình ở đâu trong trái tim cô ấy vậy.
Thử dùng selenium và thực hiện cào 1 trang web
Setup xong rồi thì mình thử xem như nào. Đầu tiên mình tạo môi trường ảo (điều luôn luôn phải làm đầu tiên khi bắt đầu $1$ project).
$ python3 -m venv venv
Activate môi trường ảo đó.
$ source venv/bin/activate
Rồi cài đặt các thư viện cần thiết trong file requirements.txt.
selenium
webdriver_manager
pandas
bs4
openpyxl
$ pip3 install -r requirements.txt
Mình sẽ thử thực hiện lấy thông tin các công ty trong trang web https://pharmed.vn/exhibitors/companies, trang web này cần có mã để accept nhé!
Đây là mẫu
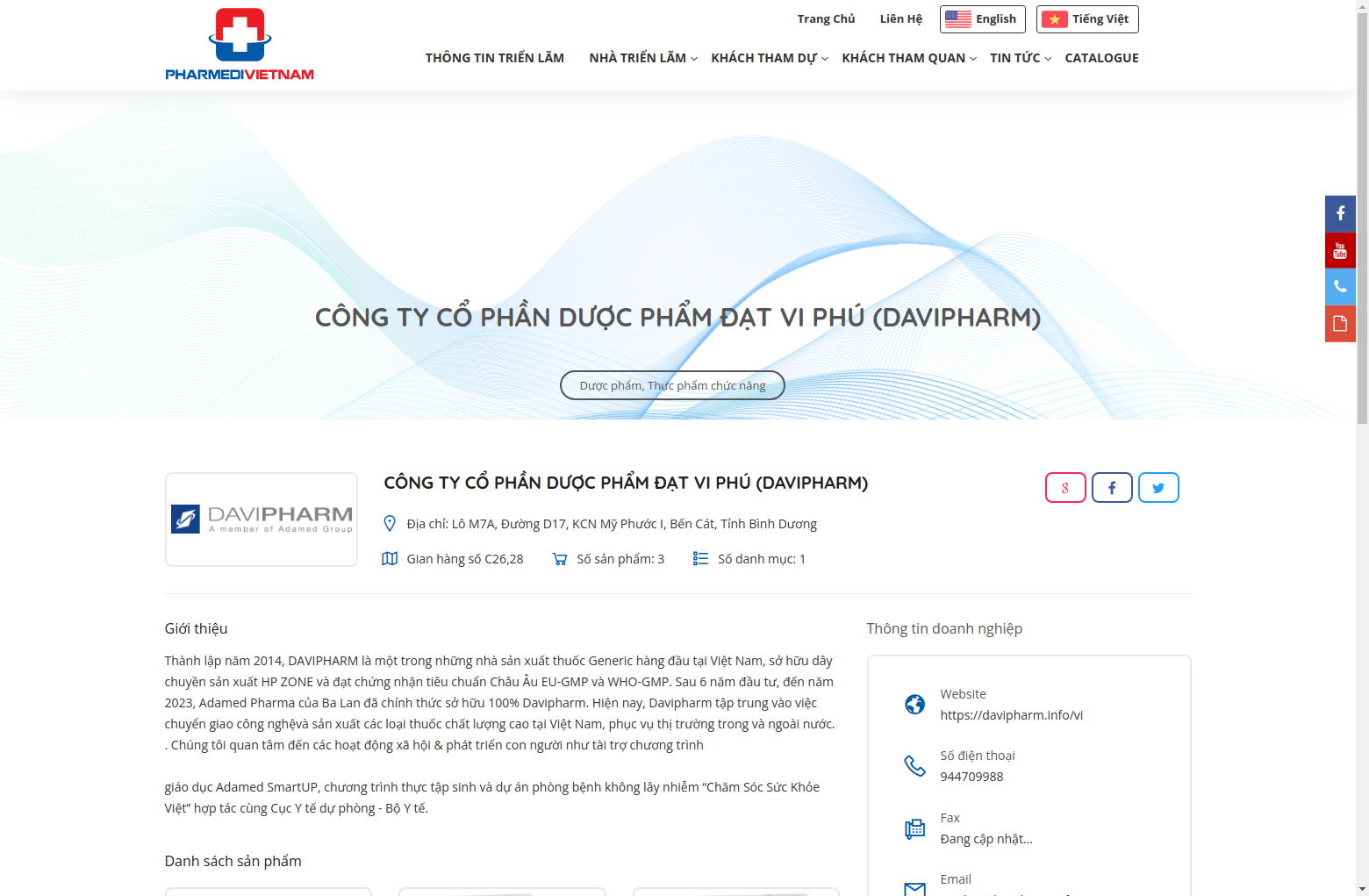
Mọi người có thể tham khảo source code của mình nhé.
# main.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
from time import sleep
from random import randint
from bs4 import BeautifulSoup
import pandas as pd
import ssl, os
ssl._create_default_https_context = ssl._create_stdlib_context
os.makedirs('screenshots', exist_ok=True)
home_url = 'https://pharmed.vn/exhibitors'
url_companies = home_url + '/companies?page={page_number}'
url_detail = home_url + '/company/{company_id}'
# Khởi tạo ChromeDriver
service = Service(ChromeDriverManager().install())
chrome_options = Options()
chrome_options.add_argument("--start-maximized")
chrome_options.add_argument("disable-notifications")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument('--headless')
chrome_options.add_argument('--incognito')
def csv_to_xlsx(path):
"""
Converts a CSV file to an XLSX file.
Args:
path: Path to the input CSV file.
"""
# Read the CSV file
df = pd.read_csv(path)
# Save to an Excel file
df.to_excel(f'{path[:-4]}.xlsx', index=False)
return True
def scroll_down_until_element_found(driver, xpath, scroll_pause_time=1):
"""
Scrolls down the page until the element specified by the given XPath is found.
Args:
driver: WebDriver object (Selenium).
xpath: XPath string to locate the target element.
scroll_pause_time: Time in seconds to pause between scrolls (default: 1).
"""
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
try:
# Check if the element is present on the page
element = driver.find_element(By.XPATH, xpath)
if element:
print("Element found!")
break
except NoSuchElementException:
pass
# Scroll down to the bottom of the page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait for the page to load
sleep(scroll_pause_time)
# Calculate new scroll height and compare with the last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
print("Reached the bottom of the page, element not found.")
break
last_height = new_height
def enter_code(driver):
'''
Accept the code and submit the search form
Args:
driver: WebDriver object (Selenium).
'''
input_xpath = '//div[@class="job-field"]//input'
keyword = 'JP3HP'
driver.find_element(By.XPATH, input_xpath).send_keys(keyword)
print(f'Entered keyword: {keyword}')
sleep(1)
submit_xpath = '//button[@type="submit"]'
driver.find_element(By.XPATH, submit_xpath).click()
print('Submitted search form')
sleep(1)
def get_company_info(driver):
'''
Get company information
Args:
driver: WebDriver object (Selenium).
'''
data = {}
soup = BeautifulSoup(driver.page_source, 'html.parser')
data['name'] = soup.find('div', class_='job-single-info3').h3.text
data['logo'] = soup.find('div', class_='job-thumb').img['src']
data['address'] = soup.find('div', class_='job-single-info3').span.text.split('Địa chỉ:')[-1].strip()
data['description'] = soup.find('div', class_='job-single-info3').find('ul').find_all('li')[0].text.strip()
data['about'] = soup.find('div', class_='job-details').p.text
overviews = soup.find('div', class_='job-overview').find('ul').find_all('li')
overviews = {item.find('h3').text.lower(): item.find('span').text.strip() for item in overviews}
data.update(overviews)
return data
def get_link(driver, pages):
'''
Get company links
Args:
driver: WebDriver object (Selenium).
pages: List of page numbers.
'''
links = []
for page_number in pages:
driver.get(url_companies.format(page_number=page_number))
sleep(randint(1, 2))
page_xpath = '//div[@class="pagination pagination-homepage-v2"]'
scroll_down_until_element_found(driver, page_xpath)
link_path = '//div[@class="job-title-sec"]//h3//a'
link = driver.find_elements(By.XPATH, link_path)
links.extend([l.get_attribute('href') for l in link])
return links
def get_data(driver, links, output = 'pharmed.csv'):
'''
Get company data
Args:
driver: WebDriver object (Selenium).
links: List of company links.
output: Output file path.
'''
stop_xpath = '//footer[@class="style2"]'
for idx, link in enumerate(links, 1):
try:
print(f'> {idx}/{len(links)} -> {link}')
driver.get(link)
sleep(randint(1, 2))
scroll_down_until_element_found(driver, stop_xpath)
data = get_company_info(driver)
name_screen = link.split('/')[-1]
driver.save_screenshot(f"./screenshots/{name_screen}.png")
data['link'] = link
df = pd.DataFrame([data])
df.to_csv(output, index=False, mode='a', header=not os.path.exists(output))
except Exception as e:
write_log(f'> {idx}/{len(links)} -> {link}: {e}')
def write_log(text):
'''
Write log to file
Args:
text: Log message.
'''
with open('log.txt', 'a', encoding='utf-8') as f:
f.write(text+'\n')
if __name__ == "__main__":
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get(url_companies.format(page_number=1))
sleep(randint(1, 2))
enter_code(driver)
links = get_link(driver, range(1, 25))
get_data(driver, links)
driver.quit()
Tips nhỏ để các bạn có thể xem giao diện trong đó chính là dùng
driver.save_screenshot(<path_save>)
Chúc các bạn thành công!